
L'intérêt majeur d'un pipeline devops est d'automatiser les étapes de livraison logicielle et ainsi gagner en temps et en fiabilité dans le déploiement de vos développements.
Mais pour que ce pipeline tienne toutes ses promesses, encore faut-il se poser les bonnes questions avant de le bâtir et adopter de bonnes pratiques devops pour le mettre en oeuvre.
On vous guide sur le sujet à travers ces quelques conseils.

1 - Savoir pourquoi on met en place un pipeline
Un pipeline est une séquence d'étapes permettant de standardiser et faciliter la livraison de logiciel vers un environnement donné. Le pipeline est généralement déclenché lors de l'envoi de code vers le dépôt.
L'intérêt de ce type de démarche dans une approche devops est d'avoir une séquence reproductible de préparation du logiciel avant sa mise en production.
Comme une chaîne dans une usine, les étapes se succèdent et peuvent être bloquantes, auquel cas l'étape suivante ne pourra pas être jouée et la chaîne s'arrête. Une correction devra être apportée pour que la chaîne puisse être relancée, depuis le début. Certaines étapes a contrario peuvent, elles, être informatives et non bloquantes.
L'objectif de cette chaîne est d'une part d'améliorer progressivement la qualité des livrables, d'autre part de le faire de façon automatisée.
Le pipeline étant l'élément de base lorsqu'on souhaite mettre en place de l'intégration continue (Continous Integration ou CI) ou de la livraison continue (Continous Delivery ou CD), il est impératif que sa mise en place soit comprise et utilisée par l'ensemble des acteurs responsables du logiciel. La mise en place de ce processus ne doit pas être contournable.
Si l'on zoome sur l'anatomie d'un pipeline, celui-ci se compose de plusieurs étapes, qui se déroulent en parallèle ou en séquence :
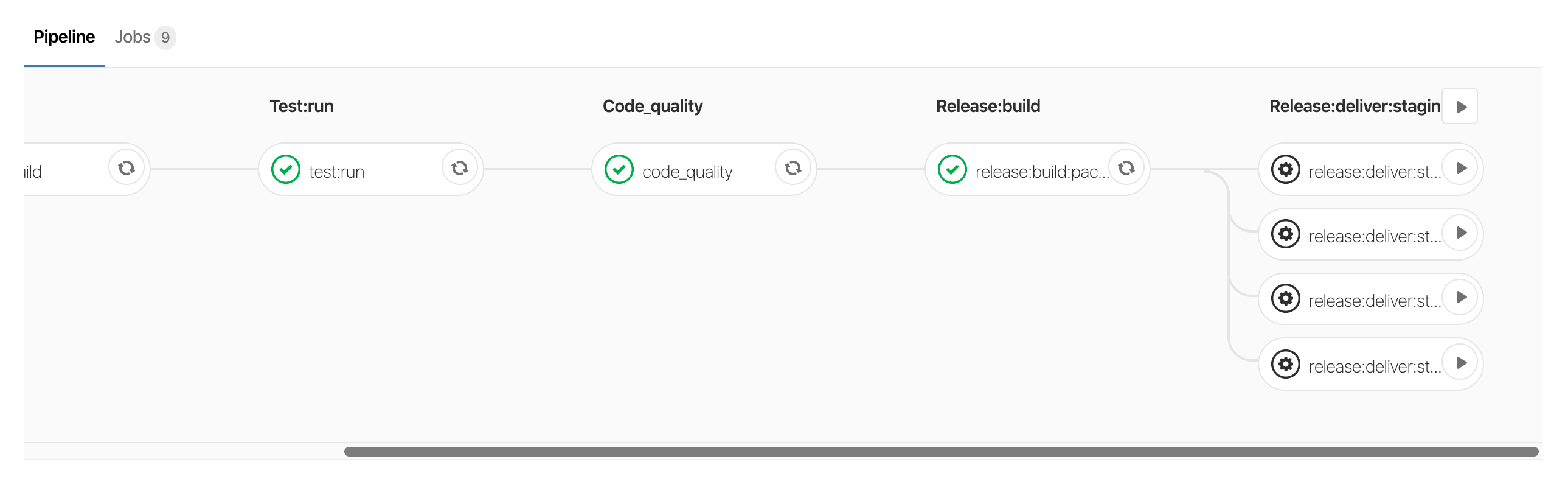
Exemple de pipeline avec gitlab
Dans cet exemple, on observe une étape durant laquelle les tests sont joués, puis une seconde durant laquelle la qualité du code est analysée, etc.
Lorsqu'une étape est validée (coche verte), l'étape suivante peut alors être jouée ; si elle avait été rouge, les étapes suivantes n'auraient pu être jouées et notre pipeline aurait été considéré comme en échec.
On observe que les dernières étapes (deliver) n'ont pas été lancées : cela est dû au fait que ces étapes sont manuelles. Elles pourraient être activées en cliquant sur le bouton « play » et lancées en séquence : chaque job permettant d'envoyer vers un environnement différent.
2 - Identifier les objectifs du pipeline
Comme toujours, il est préférable de commencer avec des objectifs modestes mais clairement identifiés, afin d'éviter d'avoir une marche trop importante à franchir. Quels que soient les objectifs visés, la finalité d'un pipeline reste de construire une ou plusieurs applications afin qu'elles puissent être déployées dans un environnement donné.
Il est également important de définir ce qui est acceptable en terme de temps d'exécution du pipeline, de consommation de ressources, de temps (humain) qu'on peut y consacrer et des gains qu'on estime obtenir suite à sa mise en place.
Notre conseil serait donc de se focaliser sur cette partie : avoir les étapes permettant de construire le livrable dans un premier temps. Il peut s'agir d'une image Docker, Vagrant, d'un WAR, JAR ou autre.
3 - Définir les étapes clés du pipeline
Une fois les objectifs en tête, on peut commencer à définir les étapes constitutives de son pipeline.
Une bonne chaîne de build peut se composer par exemple des étapes suivantes :
- Lancement des tests unitaires, d'intégration
- Lancement des best practices de l'équipe (linter, analyse de code smell)
- Lancement des détections de vulnérabilités (npm audit, brakeman)
- Construction des images applicatives (packaging)
- Déploiement dans un environnement donné
On peut aller très loin dans la mise en place de ces pipelines et adopter des comportements différents selon les évènements qui surviennent sur le dépôt de code.
En effet, on peut décider d'avoir un processus plus complexe lors de la préparation d'une release que lors de l'envoi de code relatif à une nouvelle fonctionnalité. Comme vu précédemment, il est de bon ton d'avoir des objectifs chiffrés sur les temps d'exécution acceptables.
Pour un processus standard (envoi de code pour une fonctionnalité), un temps d'exécution de 10 min nous semble un bon compromis. Dans les faits, ce temps ne doivent pas être bloquants pour les équipes de développement, qui sont outillées pour que les vérifications faites dans le CI le soient également en local avant envoi (linter, tests).
Pour autant, on imagine bien qu'il n'est pas judicieux d'avoir un pipeline qui prend une heure pour un commit dans une branche de feature. Même si ça ne bloque pas les équipes, ça mobilise des ressources machines qui sont généralement partagées.
Dans votre outil, vous aurez un certain nombre de processus qui peuvent jouer les différentes étapes de vos pipelines, mais progressivement, vous aurez de plus en plus de pipelines qui seront joués en parallèle (parce que plusieurs personnes contribuent au projet et/ou parce que vous avez plusieurs projets existants). Il faut donc veiller à toujours avoir l'œil sur le temps d'exécution et les ressources consommées.
À l'inverse, cela peut avoir pleinement du sens qu'un pipeline dure 1 heure lorsqu'on tag une release avant envoi en production. On peut imaginer une étape qui va provisionner un environnement de recette complet pour aller jouer des tests end-to-end dessus afin d'assurer la conformité du produit. Ce pipeline-là doit être le plus exhaustif possible.
4 - Mutualiser les éléments communs
Comme du code, le processus sous-jacent au pipeline doit être vivant et évoluer. Par exemple, dans certains de nos pipelines, nous avons mis en place des images de base, qui contiennent toutes les dépendances de l'application.
Précédemment, nous avions plusieurs étapes du pipeline qui recréaient une image applicative, par exemple pour jouer les tests, compiler des assets, etc. Or, ces images s'avéraient strictement identiques et il était donc préférable d'avoir une étape qui construisait une et une seule image pouvant être ré-utilisée par ces différentes étapes.
En creusant encore, nous nous sommes rendus compte qu'il n'était pas nécessaire de regénérer cette image de base à chaque pipeline, car elle ne change pas forcément entre deux pipelines. En effet, ce n'est le cas que si les dépendances de l'application ont changé.
Progressivement, nous avons donc raffiné nos processus pour avoir des pipelines de plus en plus rapides.
5 - Choisir les bons outils
La vélocité des pipelines est aussi tributaire des outils que l'on utilise. Dans notre exemple, nous utilisons un pipeline pour créer deux images applicatives : une image avec des fichiers statiques (assets) et une image applicative (app).
Précédemment, nous utilisions Docker pour construire nos images (en réalité docker in docker), ce qui s'est révélé relativement lent et obligeait le processus en charge de la construction de l'image à disposer de droits étendus (root). En passant sur kaniko, nous avons pu accélérer nettement la rapidité de création des images tout en le faisant en espace utilisateur.
Il ne s'agit là que d'un exemple particulier, mais les outils évoluent en permanence et il est important de conserver un regard critique sur les processus et outils que l'on utilise pour continuer à les améliorer.
6 - Renforcer son pipeline
C'est lorsque l'on est serein sur ses processus d'intégration continue -aussi bien au niveau des outils, processus, temps d'exécution que de leur prise en main par l'équipe-, que l'on va pouvoir les étendre.
Il est important de ne pas négliger le dernier point. Dans une culture devops, l'information doit être partagée et comprise par tous. Même si c'est un profil ops pur qui met à jour le pipeline, il est fondamental que les équipes de développement comprennent sa finalité et son mode de fonctionnement.
À partir de là, on peut commencer à aller plus loin. Par exemple dans la livraison continue, c'est-à-dire le fait d'envoyer automatiquement les applications sur des environnements de production ou pré-production. Également dans le renforcement des critères de qualité et de sécurité, en intégrant de nouveaux outils. Le pipeline peut tout à fait interagir avec d'autres outils pour lancer des tâches (ansible), ou provisionner des environnements (terraform).
Lorsqu'il s'agit de mettre en oeuvre votre pipeline, les seules limites sont donc... celles de votre imagination vos besoins !



